万字长文梳理JAVA线程方法的基础应用
第一章:多线程基础
在 Java 中,线程(Thread)是操作系统调度的最小单元。理解多线程,首先要从如何启动它、它经历过哪些状态、以及我们如何控制它开始。
线程的创建方式
虽然最终都是通过 Thread.start() 启动,但 Java 提供了三种主要的任务定义方式:
- 继承
Thread类:- 做法:定义一个类继承
Thread并重写run()方法。 - 缺点:Java 是单继承的,继承了 Thread 就不能再继承其他类(如 BaseService),灵活性差。
- 做法:定义一个类继承
我们直接new一个Tread类:
1 | public static void main(String[] args){ |
- 实现
Runnable接口(推荐):- 做法:实现
run()方法,并将其作为参数传递给Thread构造函数。 - 优点:解耦了“任务逻辑”与“线程资源”。多个线程可以执行同一个
Runnable实例,适合资源共享。
- 做法:实现
Runnable 接口。Runnable 是 Java 中一个功能性的接口,它定义了一个 run() 方法。实现这个接口的类(如 TaskRunnable)表示一个任务,这个任务可以被一个线程执行。
Thread 与 Runnable:Thread 类用于表示一个执行的线程,但它并不直接定义要做什么。Thread 需要一个 Runnable 对象,来确定线程启动后应该执行什么样的任务。所以,Thread 会将一个 Runnable 对象传给其构造方法,这样线程就知道了执行什么任务。
我们实现一个runnable接口:
1 | public static void main(String[] args) { |
- 实现
Callable接口:- 做法:实现
call()方法,配合FutureTask或线程池使用。 - 核心区别:
call()方法有返回值且允许抛出异常,而run()不行。
- 做法:实现
我们来实现一个Callable 接口
1 | public class CallableBaseDemo { |
综上,三种实现方式的区别在于:
| 特性 | Thread | Runnable | Callable |
|---|---|---|---|
| 继承性 | 限制单继承 | 无限制 | 无限制 |
| 返回值 | 无 | 无 | 有 (Future获取) |
| 异常抛出 | 只能内部捕获 | 只能内部捕获 | 允许 throws 抛出 |
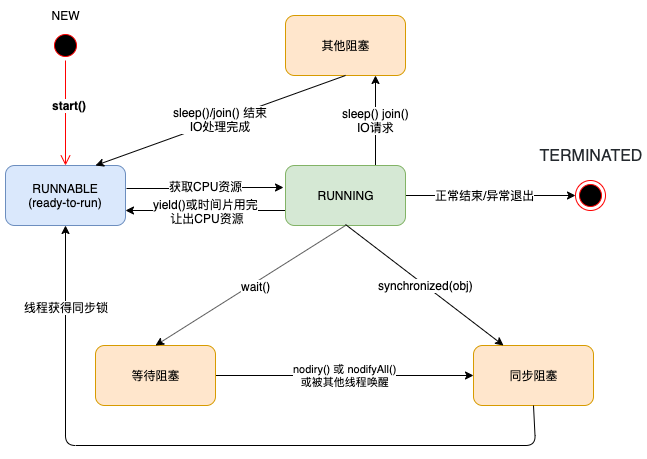
线程的生命周期与状态转换 (State Machine)
Java 线程在生命周期内并不是一直占着 CPU 不放,它会在多种状态间切换。通过 thread.getState() 可以获取以下六种状态:
-
NEW (新建):
new Thread()之后,调用start()之前。 -
RUNNABLE (可运行):调用了
start()。在 Java 中,就绪(Ready)和运行中(Running)统称为“可运行”。 -
BLOCKED (阻塞):等待获取
synchronized锁。 -
WAITING (等待):调用了
wait()、join()或LockSupport.park()。需要被其他线程显式唤醒。 -
TIMED_WAITING (超时等待):调用了
sleep(ms)、wait(ms)等。时间到了自动苏醒。 -
TERMINATED (终止):
run()方法执行完毕或因异常退出。
基础控制方法
这一节介绍的是 Java Thread 类中提供的几个核心控制方法,它们决定了线程在执行过程中的行为。
1. sleep(long millis)
sleep 是静态方法,使当前线程进入 TIMED_WAITING 状态,暂停执行一段时间。
- 锁的行为:线程在睡眠时不会释放它持有的任何锁(Monitor Lock)。
- 异常处理:睡眠中的线程如果被中断,会抛出
InterruptedException。
1 | try { |
2. yield()
yield 也是静态方法,它表示当前线程愿意让出 CPU 的使用权。
- 调度结果:调用后,线程从“运行中”变为“就绪”状态。
- 局限性:这只是一个“建议”,线程调度器可能会忽略它。如果当前没有其他同优先级的线程,该线程可能立即再次获得 CPU。
- 锁的行为:同样不会释放锁。
3. join()
join 是成员方法,用于同步多个线程的执行顺序。
- 作用:如果在线程 A 中调用
B.join(),则 A 线程会进入 WAITING 状态,直到 B 线程执行完毕。 - 原理:底层调用的是
Object.wait()方法,因此调用者会释放掉 B 线程对象的锁。
1 | Thread t1 = new Thread(() -> { /* 耗时任务 */ }); |
4. interrupt()
Java 采用的是协作式的中断机制,而不是暴力停止。
- interrupt():将目标线程的中断标志位设为
true。 - isInterrupted():实例方法,判断线程是否被中断。
- 静态 interrupted():检查当前线程的中断状态,并清除标志位。
- 特殊情况:如果线程正阻塞在
sleep、wait、join等方法上,interrupt()会使这些方法抛出异常,并自动清除中断状态(变回false)。
1 | while (!Thread.currentThread().isInterrupted()) { |
5. 守护线程 (Daemon Thread)
Java 中的线程分为“用户线程”和“守护线程”
- 定义:守护线程是为用户线程服务的(如 GC 垃圾回收)。
- 退出机制:当 JVM 中所有的用户线程都运行结束时,守护线程会随 JVM 一起直接退出,无论其任务是否完成。
- 限制:必须在
thread.start()之前调用setDaemon(true)。
举个例子:
1 | public static void main(String[] args){ |
第二章:线程安全与内存模型 (Safety & JMM)
线程安全的核心在于:当多个线程访问一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替执行,也不需要进行额外的同步,调用这个对象的行为都可以获得正确的结果,那这个对象就是线程安全的。
什么是线程安全?
要实现线程安全,必须保证并发编程的三大特性:
-
原子性 (Atomicity):一个或多个操作,要么全部执行且在执行过程中不被任何因素打断,要么全部不执行。
- 典型问题:
i++包含读、加、写三步,在多线程下不具备原子性。
- 典型问题:
-
可见性 (Visibility):当一个线程修改了共享变量的值,其他线程能够立即得知这个修改。
- 原因:JMM 规定线程有工作内存,修改变量后不会立即同步到主内存。
-
有序性 (Ordering):程序执行的顺序按照代码的先后顺序执行。
- 原因:编译器和处理器为了优化性能,往往会对指令进行重排序。
synchronized 关键字
synchronized 是一种互斥锁,它通过控制多个线程对共享资源的访问,一次只允许一个线程执行,从而同时保证了原子性、可见性和有序性。
synchronized 底层依赖 JVM 的 Monitor(监视器锁)。编译后会生成 monitorenter 和 monitorexit 指令。每个对象头中都有 Mark Word,记录了锁的状态(偏向锁、轻量级锁、重量级锁)。
下面是两个不同的应用:
synchronized 方法
在一个方法上使用 synchronized,可以保证同一时刻只能有一个线程访问该方法。这对于涉及共享资源的操作很有用,防止多个线程同时修改资源导致状态不一致。
1 | public synchronized void someMethod() { |
synchronized 代码块
有时候我们并不需要整个方法都保持同步,而是只需要某部分代码在执行时是互斥的。此时,我们可以使用 synchronized 代码块。通过指定一个对象锁来控制代码块的同步。
1 | synchronized (锁对象) { |
-
锁对象:它可以是任意对象,通常是一个共享对象。synchronized关键字会将该对象作为锁,只允许一个线程在同一时间进入该代码块。 -
如果多个线程试图同时进入该同步代码块,它们必须等待其他线程释放该锁。
-
方法级锁:当你用
synchronized修饰一个方法时,锁的粒度是方法级别的。只有一个线程能访问方法中的同步部分。 -
代码块级锁:使用
synchronized代码块时,锁的粒度是代码块级别的。它只锁定特定的资源,而不是整个方法,这样可以提高性能,因为不必要的代码部分不会被同步。
wait() 方法使当前线程进入 等待状态,直到另一个线程发出通知(通过 notify() 或 notifyAll())。当线程调用 wait() 时,它会释放当前持有的对象锁,并且进入 等待队列,直到被其他线程唤醒。
wait() 必须在 同步代码块 或 同步方法 中调用,因为它需要获得对象的监视器锁(即 synchronized 锁)。当线程在同步方法或同步代码块中调用 wait() 时,它会释放对象的锁,允许其他线程获得锁。
1 | synchronized (someObject) { |
notify() 方法唤醒 一个等待中的线程。当线程调用 notify() 时,它会从等待队列中随机选择一个线程,并将其唤醒,唤醒后的线程会尝试重新获取对象锁,获得锁后才会继续执行。
notify()必须在 同步代码块 或 同步方法 中调用。- 被唤醒的线程不会立即执行,而是进入 可运行状态,等待获取对象锁。
notifyAll() 方法唤醒 所有等待中的线程。与 notify() 不同的是,notifyAll() 会唤醒所有等待该对象锁的线程。所有唤醒的线程会争夺锁,只有获得锁的线程才会继续执行。
1 | class SharedBuffer { |
volatile 关键字
volatile 是 Java 提供的最轻量级的同步机制,它保证了可见性和有序性,但不保证原子性。
- 可见性原理:写一个
volatile变量时,JMM 会把该线程对应的工作内存值立即刷新到主内存;读时,会使本地内存失效,直接从主内存读取。 - 禁止重排序:通过插入内存屏障,确保编译器不会为了优化而改变指令顺序。
为了举例,我们介绍java中的双重检查锁定(Double-Checked Locking,DCL),主要是为了解决单例模式(Singleton)在多线程环境下的性能和安全平衡问题。
如果没有 DCL,我们最简单的同步写法是:
1 | public synchronized static Singleton getInstance() { |
每次调用 getInstance() 都要加锁,而实际上只有第一次创建实例时才需要同步,后续读取直接返回即可。加锁是非常重的操作,这会严重拖慢性能。那么,我们可以先判断是否为 null,如果不为 null 直接返回;如果为 null,再进入同步块创建对象。
1 | public class Singleton { |
我们来看 原来的instance = new Singleton(); 这一行。在 JVM 层面,它其实被分成了 3 个步骤执行:
- 分配内存空间(给这个对象找块地方)。
- 初始化对象(执行构造函数里的逻辑)。
- 将 instance 变量指向分配的内存地址(此时 instance 不再是 null 了)。
问题出在编译器的优化上: 由于步骤 2 和步骤 3 之间没有必然的依赖关系,编译器或 CPU 可能会为了提高效率进行指令重排序,把顺序变成: 1(分配内存) -> 3(指向地址) -> 2(初始化对象)。
这会导致下面发生的灾难场景:
- 线程 A 进入同步块,执行
instance = new Singleton()。 - 由于重排序,线程 A 先执行了步骤 3(指向地址),此时
instance已经不是 null 了,但步骤 2(初始化)还没完成。 - 就在这一瞬间,线程 B 调用
getInstance(),它判断instance != null,于是开心地直接把这个 instance 拿去用了。 - 结果线程 B 在使用对象时,发现由于还没初始化,内部属性全是空的,直接报出 空指针异常(NPE) 或逻辑错误。
在 instance 变量上加上 volatile 关键字后,会发挥两个核心作用:
- 禁止指令重排序:它会插入一个“内存屏障”,强制保证执行顺序必须是
1 -> 2 -> 3。这样当线程 B 拿到对象时,它一定已经是初始化完成的。 - 保证可见性:一旦线程 A 完成了对象的创建,线程 B 能够立即从主内存中看到
instance的最新值。
原子类 Atomic
对于简单的数值运算,使用 synchronized 太重,频繁的线程上下文切换会损耗性能。Atomic 系列工具类(如 AtomicInteger)采用 CAS (Compare And Swap) 机制实现。
- CAS 原理:包含三个参数:变量内存地址 (V)、预期原值 (A) 和新值 (B)。
- 只有当 V 的实际值等于 A 时,才将 V 修改为 B。否则说明变量已被修改,当前线程会通过自旋(死循环)不断尝试,直到成功。
从概念上来说,原子变量 = 操作不可被打断的变量
对它的操作要么全部执行完,要么完全不执行,不会被线程切换中断,因此天然线程安全,不需要 synchronized。
对于普通变量操作,如i++,看起来是一句,但实际上包含三个步骤:
- 读取 i
- i + 1
- 写回 i
如果两个线程同时执行,就可能出现:
- 两个线程都读到旧值
- 最终只加一次
这就出现了典型的 竞态条件(Race Condition)
举个简单的例子
1 | private AtomicInteger count = new AtomicInteger(0); |
线程封闭 (ThreadLocal)
如果说锁是解决“如何同步访问共享数据”,那么 ThreadLocal 则是“如何不共享数据”。它为每个线程提供一份独立的变量副本,实现线程间的数据隔离。
- 核心用途:解决数据库连接、Session 管理等场景下的线程安全问题。
举个简单的例子
1 | public class ThreadLocalDemo { |
第三章:JUC 显式锁 (Explicit Locks)
在 Java 并发工具包(JUC)中,java.util.concurrent.locks 提供了比 synchronized 更灵活、更强大的锁定机制。synchronized 又被称为内置锁,其不需要程序员过多的手动操作,而基于Lock接口实现的为显式锁,需要程序员一些手动操作才能执行。
Lock 接口与 ReentrantLock
ReentrantLock 是最常用的显式锁,它不仅完全覆盖了 synchronized 的功能,还提供了许多高级特性:
- 手动规范:使用显式锁必须遵循特定的模板。由于它不会自动释放锁,为了防止死锁,必须在
finally块中调用unlock()。
1 | Lock lock = new ReentrantLock(); |
-
可重入性:同一个线程可以多次获得同一把锁,内部通过计数器实现。
-
可中断性:使用
lockInterruptibly()获取锁时,如果线程正在等待锁,它可以响应中断信号并停止等待。 -
公平锁与非公平锁:构造函数支持传入
boolean值。公平锁会严格按照线程排队的顺序给锁,而非公平锁(默认)允许插队,通常拥有更高的吞吐量。
1 | Lock lock = new ReentrantLock(true); // 公平锁 |
- 可轮询获取锁(tryLock): 线程可以“试一试”拿锁,拿不到直接走,不会阻塞。
1 | if (lock.tryLock(2, TimeUnit.SECONDS)) { |
举个简单的例子:
1 | Lock lock = new ReentrantLock(); |
ReadWriteLock 读写锁
在很多场景下,数据是“读多写少”的。如果用普通的互斥锁,多个线程同时读也会互相排队,效率低下。ReentrantReadWriteLock 实现了“读写分离”。读写锁是对普通互斥锁的升级,允许多个线程同时读,但写操作只能有一个,并且写时不能读,即:
- 读读不互斥(并发度高)
- 读写互斥
- 写写互斥
ReentrantReadWriteLock
1 | ReadWriteLock rwLock = new ReentrantReadWriteLock(); |
多个线程可以同时拿:
1 | readLock.lock(); |
只有一个线程能拿:
1 | writeLock.lock(); |
下面是一个简单的读写锁的示例:
1 | public class ReentrantReadWriteLockDEMO { |
Condition 机制
Condition 是为了配合 Lock 使用的,它用来替代 Object.wait()/notify()。它的最大优势在于:一个锁可以关联多个 Condition(条件变量)。
在 synchronized 中,所有的线程都挤在一个等待队列里,调用 notifyAll() 会唤醒所有人。而 Condition 可以实现“精准唤醒”。
在 synchronized 里我们用:
• wait()
• notify()
• notifyAll()
在 显式锁(ReentrantLock) 中,我们不能再用它们,要用:
• await() 代替 wait()
• signal() 代替 notify()
• signalAll() 代替 notifyAll()
一个典型的应用场景是生产消费者模型, 我们可以创建两个条件:notFull(不满)和 notEmpty(不空)。生产者只唤醒等待 notEmpty 的消费者,互不干扰。
1 | class Depot { |
锁的降级 (写锁 -> 读锁)
锁降级是指:线程持有写锁 -> 获取读锁 -> 释放写锁。
这么做主要是为了保证数据的可见性和原子性。如果你先释放写锁再获取读锁,在中间的空隙,数据可能被其他线程修改了。通过锁降级,线程可以无缝地从“修改者”切换为“观察者”,且在这个过程中,数据不会被他人篡改。
下面是一个简单的例子:
1 | writeLock.lock(); |
第四章:并发协作工具类 (Synchronization Tools)
JUC(Java 并发工具包)除了提供锁之外,还提供了一系列非常有用的协作工具。如果说锁是解决资源竞争的,那么这些工具就是解决线程配合的。
倒计时器 CountDownLatch
CountDownLatch 是一个同步工具类,用来让一个或多个线程等待其他线程完成任务。
就像一个倒计时器:
• 初始有一个计数 count
• 每次调用 countDown(),计数减 1
• 当计数变成 0 时,所有在 await() 等待的线程都会继续执行
典型场景:等待多个任务都完成后继续执行
例如:
• 主线程启动 3 个子线程
• 每个子线程完成后执行 countDown()
• 主线程调用 await(),一直等待所有子线程完成
• 所有子线程完成后,主线程继续执行
1 | import java.util.concurrent.CountDownLatch; |
循环栅栏 CyclicBarrier
CyclicBarrier 是一种同步屏障,让一组线程必须等到“全部都到达屏障点”,然后同时继续执行。
特点:
• 屏障点(barrier)可以重复使用(循环 cyclic)
• 线程到达 barrier 后会阻塞
• 当所有线程都到达后,自动释放所有线程
假设要 3 个线程同时开始下一步:
1 | import java.util.concurrent.CyclicBarrier; |
输出:
1 | 线程 0 到达屏障点 |
CyclicBarrier 与 CountDownLatch 的区别
| 特性 | CyclicBarrier | CountDownLatch |
|---|---|---|
| 作用 | 让多个线程“集合,然后一起继续” | 让线程等待其他线程做完某件事 |
| 是否可重用 | ✔ 可重复使用(cyclic) | ❌ 不能重置(一次性) |
| 是否所有线程都会等待 | ✔ 是 | ❌ 通常只有一个或少量线程等待 |
| 调用方法 | await() | await() + countDown() |
| 谁减计数 | 每个线程调用 await() 都算一个到达 | 调用 countDown() 的线程 |
| 信号方向 | 大家互相等待 | 一些线程等待,另一些负责 countDown |
信号量 Semaphore
**Semaphore(信号量)**是Java 并发编程里一个非常核心的同步工具,主要用于控制同时访问某个资源的线程数量。
Semaphore = 一个“许可证”计数器,用来限制并发访问数量。
比如你有 3 台打印机,但有 10 个线程要打印文件。
Semaphore(3) 就相当于发 3 张“许可证”,同时只允许 3 个线程使用打印机。
1 | Semaphore semaphore = new Semaphore(3); // 有 3 个许可证 |
Semaphore 常用方法
| 方法 | 含义 |
|---|---|
| acquire() | 获取一个许可证,没有则阻塞 |
| acquire(int n) | 一次获取 n 个许可证 |
| tryAcquire() | 尝试获取,不阻塞,获取不到返回 false |
| release() | 释放许可证 |
| availablePermits() | 查看剩余许可证数量 |
Semaphore vs Lock / synchronized
| 对比对象 | Semaphore | Lock / synchronized |
|---|---|---|
| 核心用途 | 限制并发数量 | 同一时间只有一个线程进入临界区(互斥) |
| 支持多少线程同时进入 | 多个(取决于 permits) | 只能 1 个 |
| 是否可作为锁使用 | 可以(permits=1 时类似 mutex) | 是锁 |
公平/非公平
1 | new Semaphore(3, true); // 公平,按排队顺序 |
阶段同步 Phaser
Phaser 是 Java 并发里 最灵活、可重用、可动态注册线程的“阶段同步器”
可以理解为:一个可以分成很多阶段(phase)的同步器,每个阶段都要所有“参与者”到齐后才能进入下一阶段,并且参与者数量还可以动态增减。
| 工具 | 问题 |
|---|---|
| CountDownLatch | 一次性等待,不能复用,不能动态增加线程 |
| CyclicBarrier | 可复用,但是参与线程数固定,不能动态变化 |
| Phaser | ✔ 可复用 ✔ 可多阶段 ✔ 可动态增加/减少线程 ✔ 更灵活 |
基础使用:
1 | Phaser phaser = new Phaser(3); // 3 个参与者 |
输出为:
1 | T1 执行阶段1 |
核心方法:
| 方法 | 意义 |
|---|---|
| arrive() | 到达当前阶段,不等待 |
| arriveAndAwaitAdvance() | 到达并等待其他线程(最常用) |
| arriveAndDeregister() | 到达后退出,不再参加后续阶段 |
phaser可以动态注册线程:
1 | phaser.register(); // 新线程加入同步控制 |
一个例子
1 | Phaser phaser = new Phaser(1); // main 是 1 个参与者 |
数据交换 Exchanger
Exchanger 用于两个线程之间的数据交换。它提供一个同步点,在这个点,两个线程可以交换彼此的数据。
- 核心逻辑:当一个线程调用
exchange()时,它会阻塞直到第二个线程也调用该方法。然后两个线程交换数据并返回。 - 特性:只能成对使用(2个线程)。
- 场景:两个流水线环节的数据传递,或者遗传算法中的交叉操作。
一个简单的示例:
1 | Exchanger<String> exchanger = new Exchanger<>(); |
第五章:线程池架构 (Executor Framework)
在实际生产开发中,我们几乎从不手动 new Thread()。为了节省系统资源并提高响应速度,我们会使用线程池来管理线程。
为什么要用线程池?
创建一个 Java 线程需要调用操作系统的内核 API,这是一个昂贵的操作。
- 降低资源消耗:通过池化技术重复利用已创建的线程,减少线程创建和销毁的性能开销。
- 提高响应速度:任务到达时,无需等待线程创建即可立即执行。
- 提高线程的可管理性:线程是稀缺资源,使用线程池可以统一分配、调优和监控,防止无限制创建线程导致系统崩溃(OOM)。
ThreadPoolExecutor 核心参数
所有的线程池底层都是 ThreadPoolExecutor,包含七个核心的参数:
| 参数 | 名称 | 作用 |
|---|---|---|
corePoolSize |
核心线程数 | 线程池中常驻的“保底”线程数量,即使它们闲着也不会被销毁。 |
maximumPoolSize |
最大线程数 | 线程池允许创建的最大线程总量。 |
keepAliveTime |
存活时间 | 当线程数大于核心线程数时,多余的空闲线程能活多久。 |
unit |
时间单位 | keepAliveTime 的时间单位(秒、毫秒等)。 |
workQueue |
任务队列 | 存放待执行任务的阻塞队列(BlockingQueue)。 |
threadFactory |
线程工厂 | 用于创建新线程,通常在这里给线程起个有意义的名字。 |
handler |
拒绝策略 | 当队列满了且线程数达到最大值时,如何处理新来的任务。 |
线程池工作流程与拒绝策略
线程池的处理逻辑遵循“先核心,再队列,后最大”的原则:
- 提交任务:如果当前线程数 <
corePoolSize,直接创建新线程执行。 - 进入队列:如果线程数 ≥
corePoolSize,任务进入workQueue排队。 - 尝试扩容:如果队列满了且线程数 <
maximumPoolSize,创建非核心线程执行。 - 触发拒绝:如果队列满了且线程数 =
maximumPoolSize,执行拒绝策略。
JDK 自带的四种拒绝策略:
- AbortPolicy(默认):直接抛出
RejectedExecutionException异常,阻止系统正常工作。 - CallerRunsPolicy:“谁提交谁执行”。让提交任务的线程(比如主线程)自己去跑这个任务,从而降低任务提交速度。
- DiscardPolicy:直接丢弃任务,不予任何处理也不报错。
- DiscardOldestPolicy:丢弃队列里最老的一个任务,尝试再次提交当前任务。
工厂类 Executors
常用方法:
• Executors.newFixedThreadPool(n):固定大小线程池
• Executors.newCachedThreadPool():弹性线程池
• Executors.newSingleThreadExecutor():单线程
• Executors.newScheduledThreadPool(n):定时任务线程池
ExecutorService(线程池接口)
1 | Executor |
常用方法:
• submit():提交任务
• shutdown():优雅关闭
• shutdownNow():强制终止
ScheduledExecutorService
用于执行定时任务、周期任务。
包含:
schedule()
scheduleAtFixedRate()
scheduleWithFixedDelay()
1 | import java.util.concurrent.*; |
ForkJoinPool (分治思想)
ForkJoinPool 是一种专门用于“分而治之(Fork)+ 合并结果(Join)”的高效并行计算线程池,它用来处理大量可以拆分的任务,自动进行任务窃取(work-stealing)以提升 CPU 利用率。
你一般只需要继承:
• RecursiveAction(void 任务)
• RecursiveTask(有返回值任务)
大数组求和
1 | import java.util.concurrent.*; |
Future
Future 表示一个异步计算的结果,你可以在提交任务后立即得到 Future 对象,以后再从这个对象中取结果。
其接口为:
1 | public interface Future<V> { |
future的最常见来源:线程池的 submit() 方法。
1 | ExecutorService pool = Executors.newFixedThreadPool(3); |
得到的 future 就是异步结果句柄。
1 | ExecutorService pool = Executors.newFixedThreadPool(2); |
输出:
1 | 我先做点别的事... |
因此,future可以 通过 get() 方法获取异步执行的结果(阻塞等待)。
同时,也可以通过cancel取消任务,通过isDone判断任务是否完成,通过get(timeout)等待固定时间,如果任务还没完成,则抛 TimeoutException。
第六章:异步编程 (Asynchronous Programming)
Future 的局限性
虽然 Future 开启了异步执行的先河,但它在处理复杂业务逻辑时非常笨拙:
- 阻塞等待:要获取结果只能调用
get(),如果子线程没跑完,主线程必须在此阻塞,这实际上把异步变成了同步等待。 - 轮询耗能:如果不阻塞,就得用
isDone()开启死循环轮询,极度消耗 CPU。 - 无法回调:无法表达“任务完成后自动执行下一步”的逻辑。
- 编排困难:很难将多个
Future的结果组合在一起,代码会嵌套得非常难看(回调地狱)。
CompletableFuture
JDK 8 引入的 CompletableFuture 是异步编程的里程碑。它实现了 Future 和 CompletionStage 两个接口,支持任务的回调、组合和链式编排。
异步任务的启动与执行策略
任务的启动通常依赖于静态工厂方法。supplyAsync 用于启动具有返回值的异步计算,而 runAsync 则适用于仅需执行特定动作且无需返回结果的场景。在资源调度层面,若不指定 Executor,这些任务默认由 ForkJoinPool.commonPool() 承载,但在生产环境下,通常建议传入自定义线程池以实现业务间的资源隔离与监控。
异步链路的回调处理机制
在任务完成后,CompletableFuture 支持通过链式调用定义回调逻辑。thenApply 方法能够获取前一阶段的执行结果并对其进行转换,产生一个新的返回值,从而构建出流水线式的处理链路。与之相对,thenAccept 仅用于消费前序任务的结果而不产生新的输出,而 thenRun 则完全忽略结果,仅在任务完成这一特定时机触发后续动作。
多任务的逻辑编排与协同
针对复杂的并发场景,CompletableFuture 提供了强大的编排能力。对于存在先后依赖关系的串行任务,thenCompose 可以将前一个任务的输出平滑传递给下一个异步任务;而对于互不依赖、需并行执行的任务,thenCombine 支持在两个任务全部完成后对其结果进行聚合。在更宏观的层面,allOf 提供了阻塞式同步机制,确保所有并行的异步任务全部完成后再向下执行,而 anyOf 则实现了竞争逻辑,只要其中任意一个任务率先完成即返回其结果。
异步链路的异常捕获与容错
异步编程中的异常传播与传统同步代码有所不同,需要专门的兜底机制。exceptionally 方法类似于同步代码中的 catch 块,能够在链路出现异常时拦截错误并返回一个预设的默认值,确保后续链路不会因未捕获的异常而中断。此外,handle 方法提供了更全面的控制,无论前序任务是正常结束还是抛出异常,它均能接收到执行结果或异常对象,并进行统一的处理与转换。
举一个链式流水线的例子
1 | CompletableFuture.supplyAsync(() -> "查询商品ID:123") |
CompletionService
CompletionService<V> 是一个接口,用于 提交异步任务并按完成顺序获取结果。它结合了 Executor(线程池)和 BlockingQueue 的功能。任务完成顺序与提交顺序可能不同,使用 CompletionService 可以 按照完成顺序 获取任务结果。
1 | import java.util.concurrent.*; |
第七章:并发容器 (Concurrent Collections)
ConcurrentHashMap 原理
ConcurrentHashMap 是为了解决 Hashtable 全局锁定导致并发效率低下的问题而设计的。在 Java 8 及其后续版本中,它舍弃了早期版本中的分段锁(Segment)设计,转而采用 Node 数组 + 链表 + 红黑树 的结构,并结合 CAS(Compare-And-Swap) 和 synchronized 实现更细粒度的锁控制。
在执行读操作时,ConcurrentHashMap 完全不加锁,通过 volatile 关键字保证了数据的可见性,这使得它在读取密集的场景下表现极佳。在执行写操作时,它仅锁定当前正在操作的哈希桶(即 Node 数组的头节点),而不是整个 Map。这种“局部锁定”的策略允许多个线程同时对不同的哈希桶进行写入。此外,当链表长度超过阈值(默认为 8)且数组容量大于 64 时,链表会转化为红黑树,以保证在高碰撞情况下的查询效率仍能维持在 。
CopyOnWriteArrayList
CopyOnWriteArrayList 采用了一种极其独特的“写时复制”(Copy-On-Write)策略。它的核心思想是:当你对容器进行修改(添加、删除、设置元素)时,它并不直接修改当前数组,而是先将原数组拷贝一份副本,在副本上完成修改操作,最后再将原数组的引用指向这个新副本。
这种机制带来了显著的特性:读操作完全无锁且不阻塞。当一个线程在遍历列表时,即使有另一个线程正在进行修改,遍历线程看到的依然是修改前的旧数组镜像,因此它天然地解决了并发修改异常(ConcurrentModificationException)。然而,这种设计也存在明显的权衡,即每次修改都会导致数组拷贝,内存开销较大。因此,它仅适用于读多写极少且对实时性要求不是极高的场景(例如配置白名单或监听器列表)。
1 | // 写操作示例:内部会加锁并复制数组 |
阻塞队列 BlockingQueue 全家桶
BlockingQueue 是实现“生产者-消费者”模型的灵魂组件。它与普通队列的区别在于支持阻塞机制:当队列为空时,尝试取出的线程会被阻塞直到有数据可用;当队列满时,尝试存入的线程会被阻塞直到队列出现空位。
JUC 提供了多种不同特性的实现类。ArrayBlockingQueue 基于定长数组,强制要求设置初始容量,适合任务量稳定的系统。LinkedBlockingQueue 基于链表,默认容量为 Integer.MAX_VALUE,如果不设限可能会导致内存溢出。SynchronousQueue 则更为特殊,它不存储任何元素,每一个插入操作必须等待另一个线程的移除操作,是线程间“手递手”传递数据的桥梁。此外,还有支持优先级的 PriorityBlockingQueue 和处理延迟任务的 DelayQueue。这些队列通过内部的 ReentrantLock 和 Condition 机制,优雅地解决了线程间的同步调度问题。
第八章 死锁
在多线程环境下,死锁(Deadlock) 是最令人头疼的并发问题之一。它发生在两个或多个线程互相持有对方所需的资源,导致所有相关线程都进入无限期的等待状态。
死锁的四大必要条件
根据经典操作系统理论,死锁的发生必须同时满足以下四个条件。如果能破坏其中任何一个,死锁就不会发生:
- 互斥条件(Mutual Exclusion):
资源是独占的。在某一时刻,一个资源(如一个对象锁)只能被一个线程持有。如果其他线程请求该资源,必须等待直到持有者释放。 - 占有且等待(Hold and Wait):
一个线程已经持有了至少一个资源,但又提出了新的资源请求,而该资源正被其他线程占有。此时请求线程阻塞,但对自己已获得的资源保持不放。 - 不可剥夺(No Preemption):
线程已获得的资源在未使用完之前,不能被其他线程强行夺走,只能由该线程在完成任务后主动释放。 - 循环等待(Circular Wait):
存在一个线程的资源循环链。例如,线程 等待 占有的资源, 等待 的资源……最后 又在等待 占有的资源。
举个例子:
1 | Object lockA = new Object(); |
在这个例子中,Thread.sleep(100) 是产生死锁的关键催化剂。它保证了 t1 锁住 lockA 的同时,t2 有足够的时间锁住 lockB。此时, 试图获取 lockB 时会因为“互斥”被阻塞,同时它“占有且等待”着 lockA; 同理。由于锁是“不可剥夺”的,最终形成了 的循环等待。
如何排查死锁?
当程序突然“卡死”且 CPU 占用率极低时,极有可能是发生了死锁。你可以使用 JDK 自带的工具进行检测:
jcmd / jps:获取运行中的 Java 进程 ID。jstack <pid>:打印线程堆栈。如果存在死锁,jstack会在末尾明确提示Found one Java-level deadlock,并详细列出是哪些线程在哪个对象上互相折磨。
如何预防死锁?
- 固定加锁顺序(破坏循环等待):这是最常用的方案。让
t1和t2都按照“先拿 A 再拿 B”的顺序去竞争,这样就不会形成环路。 - 尝试性获取锁(破坏不可剥夺):使用
ReentrantLock的tryLock(long time, TimeUnit unit)方法。如果线程在规定时间内拿不到下一把锁,就主动释放已经拿到的锁,退回并重试。 - 减小锁粒度:尽量不要在一个同步块中嵌套另一个同步块。
第九章 Thread内存泄漏
在多线程开发中,除了死锁,另一个隐蔽且高发的陷阱是 ThreadLocal 导致的内存泄漏。这通常发生在长生命周期的线程(如线程池中的线程)中。
ThreadLocal 内存泄漏的根源
ThreadLocal 的原理是为每个线程维护一个私有的 ThreadLocalMap。这个 Map 的特殊之处在于它的内部结构:其 Key(ThreadLocal 实例)是弱引用(WeakReference),而 Value(存储的数据)是强引用。
这种设计的初衷是为了保护内存:当外部不再持有 ThreadLocal 实例的强引用时,Key 会在下一次 GC 时被回收,变成 null。然而,问题也就此产生。虽然 Key 消失了,但 Value 依然被线程的 ThreadLocalMap 以强引用的方式持有。
如果这个线程是普通线程,执行完任务就销毁了,那么整个 Map 都会被回收。但现代应用几乎都在使用线程池。线程池中的线程是高度复用的,这意味着:
- 线程永远不会结束。
ThreadLocalMap里的那块 Value 内存会一直被占用。- 由于 Key 变成了
null,你再也没有办法通过正常途径访问到这块 Value,它成了一块“幽灵内存”。
比如:
1 | public class ThreadLocalLeakDemo { |
在上述代码中,虽然任务执行完了,但由于线程池里的线程没死,每个线程持有的 5MB 字节数组会一直驻留在内存中。如果任务不断提交,内存占用会持续攀升,最终导致 OutOfMemoryError。
使用 jvisualvm 或 MAT (Memory Analyzer Tool) 查看堆转储(Heap Dump)。如果你发现 ThreadLocalMap 里的 Entry 数量异常多,且其 value 字段占用了大量内存,基本可以确定是泄漏。
在代码中使用 ThreadLocal 时,务必遵循 try-finally 模式,在 finally 块中调用 remove() 方法。这会清除当前线程 Map 中对应的 Entry。
1 | try { |