介绍一下本科毕设里关于基于AIS数据进行船舶轨迹合成部分的一点思路,非专业,仅分享
写在前面
契机是我一位老师最近中了关于海运的面上,突然想起我本科毕业论文做的也是相关的数据分析。当然只是一点很简单的工作,毕竟只是本科的毕业设计。
AIS数据获取
自动识别系统(Automatic Identification System,AIS)是安装在船舶上的一套自动追踪系统,通过岸基或星基设备接收船舶唯一标识符号、坐标、类型以及航行状态等数据,并且由连续的船舶AIS数据可合成船舶轨迹。
第一步数据获取就卡了很久。定毕设题目那会儿,即2023年冬天,有幸参加了第一届的信息地理学大会,听了三四个关于AIS数据和船舶轨迹分析的报告,都有提到他们获取的AIS数据,一些研究人员手里一年的数据量都是十亿级别的,让我有种莫名的错觉,觉得获取局部一段时间内的AIS数据并不是什么难事。


事实证明,我想的太简单了。先是尝试寻找开源数据未果,开始咨询数据供应商。但是这些商业公司的服务对象一般是船运相关企业和少量的科研人员,对我这样的个体户,上千上万的起步价尚且不能接受,何况数据需求在起步价内无法满足。兜兜转转十天,终于让我找到了活菩萨网站https://datalastic.com/
其实他们的定价同样贵的离谱,月订阅费用高达数千欧元,但他提供了一个几十欧元的一周体验计划,我没有犹豫就买了这根救命稻草。有了api一切都好说,唯一的问题是其相关API只能请求一个坐标特定范围内的AIS数据,这给数据获取的策略与后期数据合成都增加了不小的难度。我只能先将研究区域划分为几十个圆,在获取这些圆心范围内的数据。大概爬取了3-4天后,从datalastic网站获取了区域内AIS记录72,9499条,包含船舶的uuid(唯一标识符)、mmsi、坐标以及速度等有效信息,并汇总数据集包含的船舶,获取了每条船舶的国籍、类型、排水量等信息,具体下表所示。
| AIS记录字段 | AIS记录字段含义 | 船舶信息字段 | 船舶信息字段含义 |
|---|---|---|---|
| uuid | 通用唯一识别码 | uuid | 通用唯一识别码 |
| lat | 纬度(度) | name | 名称 |
| lon | 经度(度) | mmsi | 海事服务身份码 |
| speed | 速度(节) | imo | 国际海事组织号码 |
| course | 航向 | country_iso | 注册国代码 |
| heading | 船首向 | type | 类型 |
| destination | 目的地 | gross_tonnage | 总吨位 |
| last_pos_epoch | 时间戳 | deadweight | 最大载运量 |
| last_pos_utc | 时间戳(世界时间) | length | 船体长度 |
| speed_max | 最大航速(节) | ||
| navstat | 导航状态 | home_port | 注册港 |
| distance_nm | 距目的地距离(海里) | year_built | 建造年份 |
| breadth | 船体宽度 |
大概分布如下图:
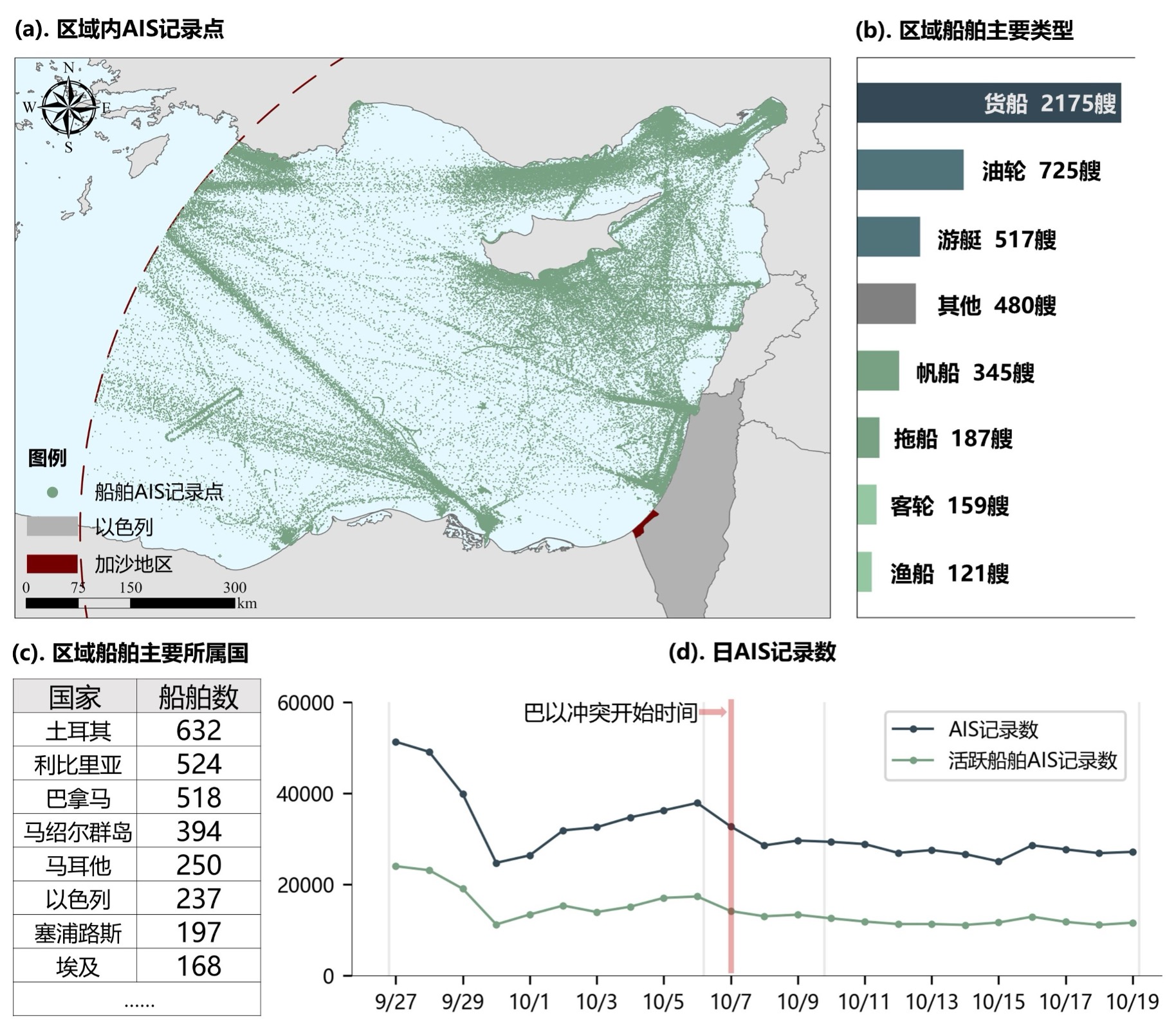
将其注入数据库,并通过uuid字段与船舶信息数据库建立连接。
船舶轨迹合成
由于用于合成船舶轨迹的AIS记录时间跨度较长,绝大多数船舶在区域内并不仅完成了一次航行任务,而是涵盖了多条航线。因此,通过AIS记录直接合成的船舶轨迹存在航迹复杂、重复等问题。为了更好地获得航行特征,研究将轨迹从港口出发,直至到达另一港口的航段定义为船舶的一条分段轨迹。而在给定的时间内,可能无法捕捉到一些船舶的起始港口或终点港口,因此被起始时间或终止时间截断的轨迹,也被称为该船舶的一条分段轨迹。
因此,通过AIS记录合成分段轨迹的前提是区分船舶的状态,即航行状态或驻留状态。在某一船舶的一组根据时间排序的AIS记录中,有四种可能的分段轨迹:
- 由该组数据最早的AIS记录点开始,至下一个处于驻留状态的AIS记录点结束的分段轨迹。
- 由该组数据最早的AIS记录点开始,至该组数据最晚的AIS记录点结束的分段轨迹。
- 该组某个处于驻留状态,且下一个记录点处于航行状态的AIS记录点开始,至下一个处于驻留状态的AIS记录点结束的分段轨迹。
- 该组某个处于驻留状态,且下一个记录点处于航行状态的AIS记录点开始,至该组数据最晚的AIS记录点结束的分段轨迹。
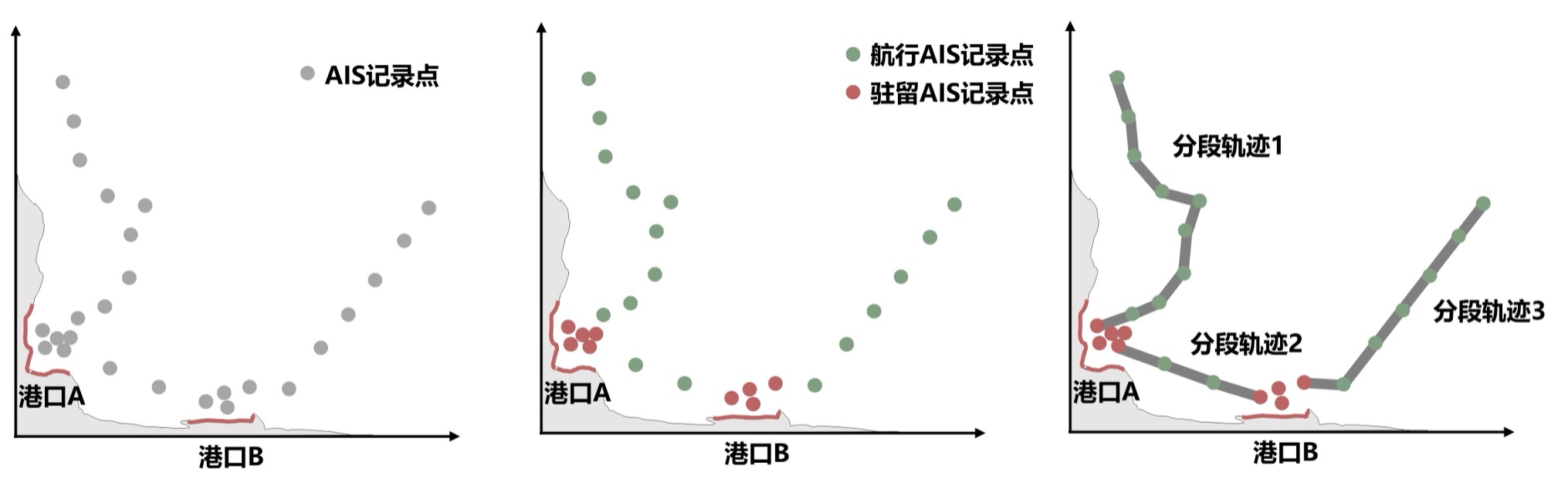
上图展示了通过判断某一船舶AIS记录点航行状态,从而合成船舶分段轨迹的步骤。虽然AIS记录提供了导航状态字段,用以判断船舶是否处于航行状态,但该字段存在大量数据缺失、错误问题。此外,研究认为,虽然在港口附近的上传的AIS记录点显示船舶处于航行状态,但该船舶的实际行为多表现为停留或在较小的范围内徘徊,因此应当被归类为驻留。因此,AIS记录的导航状态字段并不能提供准确的判别依据,研究采用支持向量机(Support Vector Machine, 下文简称SVM)方法判定AIS记录点的状态。
SVM是一种可以有效处理分类问题的机器学习算法,目标是在数据集中找到一个最优的决策边界(亦称为超平面),这个决策边界能够以最大间隔分开不同类别的数据点。
由于SVM是一种监督分类方法,因此,研究手动标注了2000个AIS数据点的航行状态,并使用坐标、航速、航向以及船首向作为特征向量,使用70%的标注数据集作为训练集训练SVM模型,同时通过比较剩下30%的数据构成的测试集检测各个核函数的区分效果,包括线性核函数、多项式核函数、径向基函数核以及Sigmoid核函数,并确定了最佳核函数。
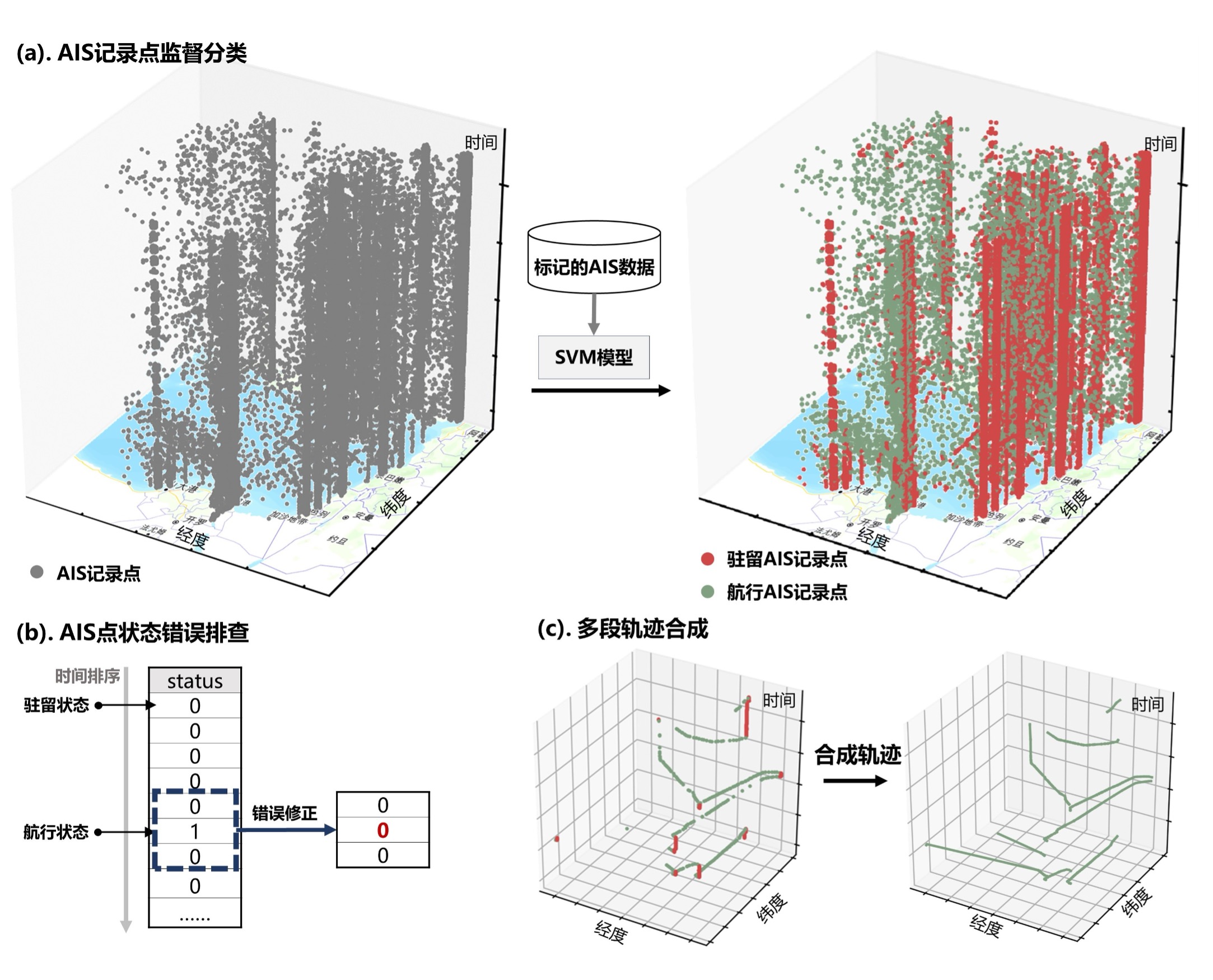
从图中可以看出,船舶驻留记录点多聚集于海岸港口,与实际情况相符。然而,由于模型仍存在一些误差,可能将一些处于航行状态的AIS记录点被识别为驻留状态,而一些处于驻留状态的航行点被识别为航行状态,导致原本连续的航行AIS记录被打断,导致船舶的分段轨迹错误地在该节点上分裂,或是从船舶驻留在港口及周边区域时识别出多余轨迹。因此,研究需要识别并修正这些错误的状态点。研究使用一个大小为3x1的滑动窗口遍历按时间排序的船舶状态记录点,如果窗口内第一个状态记录与第三个状态记录相同,但第二个状态记录与前后都不同,则修正该记录。
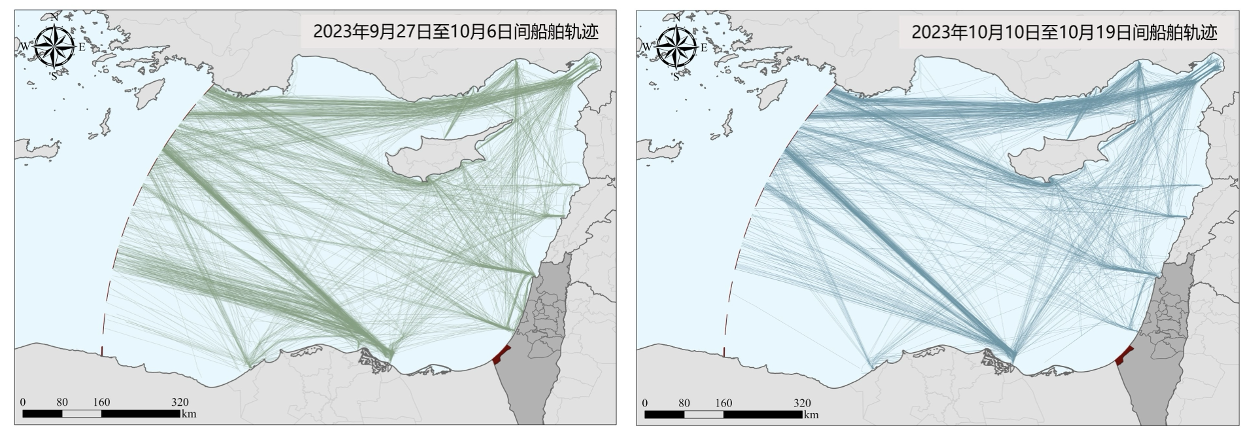
在完成数据修正后,即可合成船舶轨迹,即分段的坐标时间序列。图中©展示了某船舶的AIS记录分段轨迹合成,在合成过程中,研究删除了船舶状态为驻留的记录,并连接连续的船舶状态为航行的记录,完成了一段完整轨迹的分割。使用该方法完成2023年9月27日至10月6日,以及10月10日至10月19日区域的全部AIS记录分段轨迹合成,其效果如下图所示。
船舶轨迹压缩
Douglas-Peucker算法(以下简称DP算法)是一种用于曲线近似和抽稀的算法。它的主要思想是在给定的曲线中,通过保留一些重要的数据点,来近似表示原始曲线,从而实现曲线的简化。由于研究提供的轨迹数据集数据量较大,轨迹节点较多,因此在轨迹聚类前,对轨迹数据集进行压缩处理能够有效提高聚类效率,而大量实验证明,DP算法适用于轨迹数据的压缩。下图展示了DP算法对于一条轨迹压缩的过程。
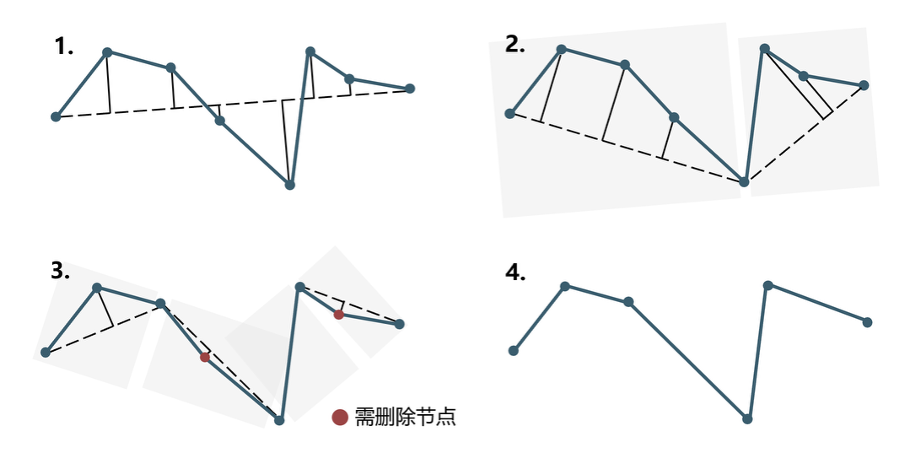
DP算法的基本思路如下:
- 在目标曲线的起点和终点之间,找到一条直线,作为曲线的初始近似。
- 计算其他所有点到该直线的距离,找到距离最大的点(即垂直距离最大的点)。
- 如果这个最大距离超过了预先设定的阈值(即所谓的抽稀阈值),则将该点加入到结果集合中,并将曲线划分为两个子曲线。
- 对两个子曲线分别递归地应用上述过程,直到所有点都被处理完毕。
通过这个过程,DP算法可以在一定程度上保留曲线的形状特征,同时减少数据点的数量,从而实现曲线的简化。DP算法的阈值决定了简化后的曲线与原始曲线之间的最大允许误差,是影响算法压缩结果的唯一参数。
Zhao等人的实验]表明,对于统一阈值压缩而言,在以一个固定的步长增加阈值的过程中,使用轨迹节点数变化率相对较低、较为平稳的一定范围内的阈值,对相似度量性能有一定程度的提升,他们称该范围为“稳定阶段”。为此,研究计算了0-1000米阈值范围内,以10米为步长的轨迹平均节点数负增长率以及轨迹平均长度负增长率,得到数据集的6个“稳定阶段”,如下图所示。
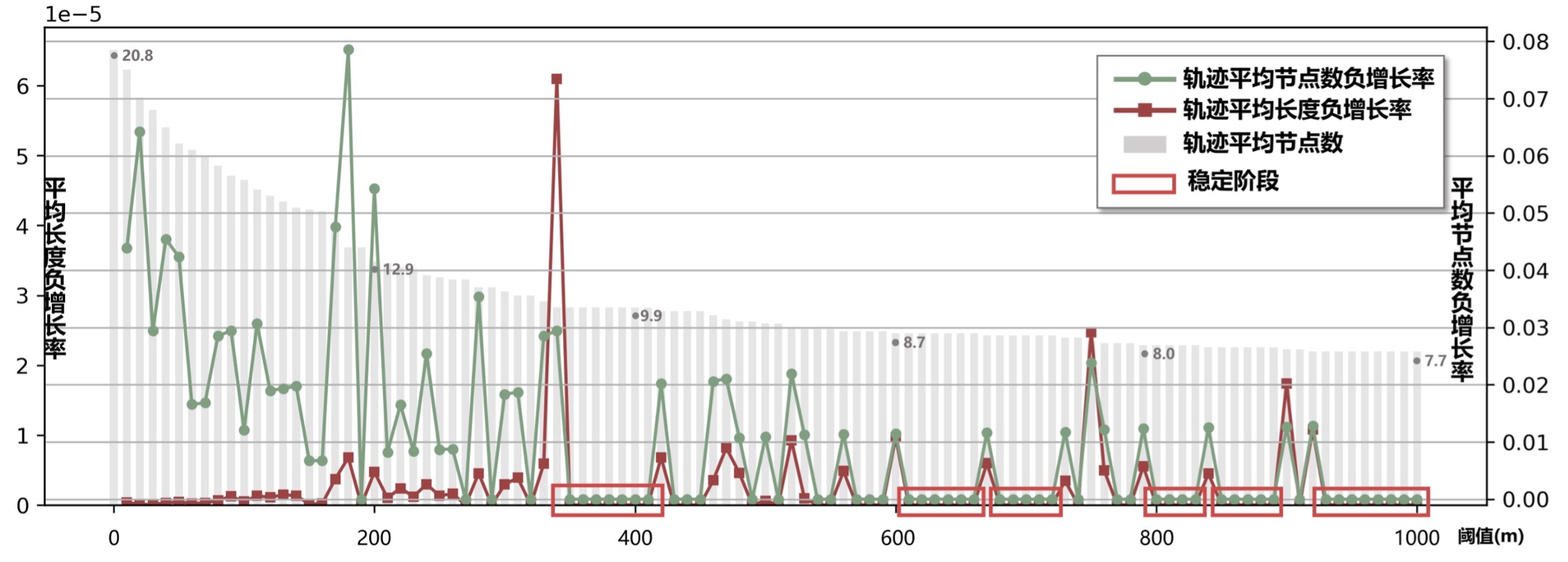
为了尽可能保全轨迹结构,研究选取了处于第一个稳定阶段的压缩阈值350m。在该阈值下,经压缩,数据集中每条轨迹的平均节点数减少至原来的44%,但平均轨迹长度仍保持在原来的98%,这说明该压缩算法在大幅度减少轨迹节点数量的同时,较好地保存了轨迹原有的形态特征。
后记
上述的AIS数据获取-分段轨迹合成-轨迹压缩构成是当时毕业设计的数据预处理部分,后续继续进行了聚类、分析等操作,这部分以后有机会再讲吧。现在回看我的毕业设计的后续部分也是稀奇古怪的,譬如修改DTW距离计算方式来消除长度导致的相关性,用一堆概率分布拟合计算最优聚类参数等等,现在觉得似乎不够严谨,但也不太清楚有什么更好的改进方法,看来水平没有进步。