最近参与了一个横向,项目架构与基础代码大概稳定下来了,浅浅记录一下。
写在前面
实际上这个项目在技术上并不难,甚至比许多工作简单的多,但让人头疼的主要是三点:
- 典型小作坊做派,前端、数据库、识别系统、模型全要做,没有明确的职责分工
- 内网开发,测试也很困难,每天要骑个电瓶车去update
- 需求含混不清,一会说用这个一会说用那个,为此接入数据的逻辑改了n遍
系统需求与架构
领导需要一个接入监控系统,实施监测各个实验室实验人员操作规范性,并归纳总结的系统,现在已在接入了一百余个监控设备,后续将推广至一千余个设备,其大致架构如下图所示:
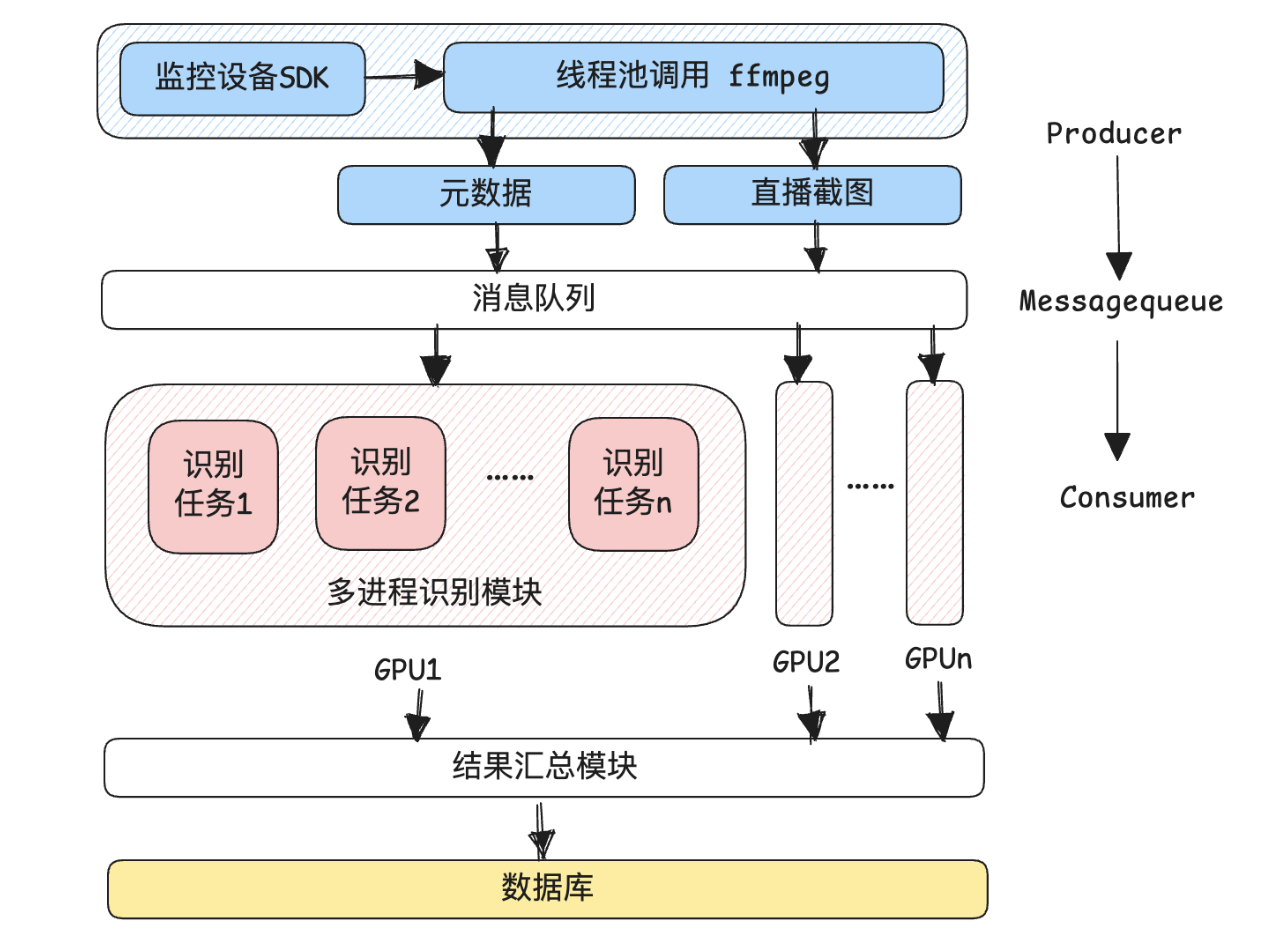
按照该架构,重点的内容为监控轮询与帧识别两部分,程序将以设定的轮询间隔依次通过厂商提供的SDK访问摄像头并截图,将截图与包括摄像头基础信息、时间等的元数据交予消息队列并分发给多个识别设备进行图像识别。在试运行版本中,整个体系都在一台一张gpu的设备上运行。图像识别完成后,将识别结果汇总后存入数据库中。
任务模型训练
甲方提出了识别实验室实验人员不穿白大褂、夜间单人做实验、消防通道占用、废液桶是否盖盖子、通风橱开启是否规范等等。这些需求有的可以直接调用YOLO模型,有的则需要自行训练模型。
以实验人员穿着为例,首先基于YOLOv11模型提取多张监控截图中的人物边框并裁减,使用自己设计的标注工具进行是否穿着实验服装的正负样本标注,约两千余张。使用该数据,基于MobileNetV2模型训练我们需求的分类模型。
MobileNetV2 是 Google 在 2018 年提出的一种轻量级卷积神经网络架构,我们将其迁移至我们的任务上。具体任务流程与要点如下:
- 按照8:2划分数据集
- 加载 ImageNet 上预训练好的权重
- 将MobileNetV2 的最后一层
nn.Sequential替换为输出 2 类
- 任务采用交叉熵损失函数, Adam优化器,训练 epochs=10, batchsize=32, lr=1e-4
最终,分类模型的Accuracy为0.9850,达到了预期需求。
整体模型首先使用yolo11s识别人,置信阈值设置为0.4,随后使用自己训练的二分类模型进行是否穿白大褂的判别,在后续的测试中,发现其基本可以满足需求,但仍对穿着白色T恤的实验人员有漏检情况,需要后续对模型进行改进。
Producer模块设计
读取数据库中当日需要访问的摄像头的id,基于摄像头厂商提供的监控rtsp视频流Python SDK,轮询摄像头获取rtsp url。一开始使用opencv链接流并截取帧,但是截取效率和内存占用都很不理想,后来就直接改用了ffmpeg截取,在处理速度和内存占用上都优化了许多。
由于仍存在一定的等待时间,采用线程池提交任务,大概逻辑如下:
1
2
3
4
5
6
7
8
9
|
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
futures = [executor.submit(ffmpeg_cut, *task) for task in tasks]
for future in concurrent.futures.as_completed(futures):
try:
result = future.result()
except Exception as e:
print(f"Task raised an exception: {e}")
|
在截取完成图像后,保存至本地并将元数据加入消息队列。
消息队列设计
在单机任务中,任务队列由Python维护,设计一个PhotoMessage类如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| @dataclass
class PhotoMessage:
"""
Attributes:
photo_id: 帧的唯一标识符(默认使用 UUID)
camera_id: 摄像头的标识符
room_id: 物理位置的标识符
photo_path: 帧在文件系统中的路径或内存引用
timestamp: 帧的捕获时间(如果未提供则自动生成)
metadata: 附加的处理上下文信息(如模型输出等)
"""
camera_id: str
room_id: str
photo_path: Path
photo_id: str = field(default_factory=lambda: str(uuid.uuid4()))
timestamp: datetime = field(default_factory=datetime.now)
metadata: Dict[str, Any] = field(default_factory=dict)
def to_json(self) -> str:
|
其中,有如 photo_id 是运行时生成一个唯一值(不能提前固定成某个默认字符串)。如果你写 photo_id: str = str(uuid.uuid4()),那么所有对象都会默认用同一个 UUID(因为默认值只会在类定义时求一次值)。而default_factory 会在每次创建对象时调用 lambda 生成新的值。在 dataclass 中,凡是带副作用的默认值(当前时间、UUID、列表、字典等)都应使用 default_factory,否则会引发不可预测的行为或共享状态。
为了表示队列,设计一个GlobalMessageQueue类如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| class GlobalMessageQueue():
_instance = None
def __new__(cls):
if cls._instance is None:
cls._instance = super().__new__(cls)
cls._instance._queue = queue.LifoQueue(maxsize=10000)
cls._instance._persist_file = None
return cls._instance
def put_message(self, msg: PhotoMessage) -> bool:
"""
存入消息到队列
:param msg: PhotoMessage实例
:return: 是否成功入队
"""
try:
self._queue.put_nowait(msg)
return True
except queue.Full:
print("WARNING: 消息队列已满,丢弃最早的消息")
try:
self._queue.get_nowait()
self._queue.put_nowait(msg)
return True
except queue.Empty:
return False
def get_message(self) -> Optional[PhotoMessage]:
"""
非阻塞获取消息
:return: PhotoMessage实例或None
"""
try:
return self._queue.get_nowait()
except queue.Empty:
return None
def persist_messages(self, file_path: Path) -> int:
"""
持久化队列到磁盘
:param file_path: 存储文件路径
:return: 持久化的消息数量
"""
def load_messages(self, file_path: Path) -> int:
"""
从磁盘加载消息到队列
:param file_path: 存储文件路径
:return: 加载的消息数量
"""
return count
def set_persist_file(self, file_path: Path):
"""设置自动持久化文件路径"""
def __del__(self):
"""析构时自动持久化"""
def size(self) -> int:
"""
获取当前队列的大小
:return: 队列中消息的数量
"""
|
该类 GlobalMessageQueue 实现了线程安全的全局单例消息队列,使用 LifoQueue 存储 PhotoMessage 实例,支持消息的入队、出队、磁盘持久化和加载,并在对象销毁时自动保存队列内容,防止数据丢失。
当然,在多设备并行处理中,可使用Redis作为多设备共享的消息队列。
Consumer模块设计
首先,我们定义一个父类BaseModel,规范了模型对于图像输入的预处理方式。配置从指定config中读取,规范模型的名称、权重文件位置、预处理方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| class BaseModel():
def __init__(self, config: Dict[str, Any]):
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.name = config["name"]
self.preprocess = config["preprocess"]
self.pipeline = config["pipeline"]
self._build_preprocess_method()
def _build_preprocess_method(self):
preprocess = self.preprocess
def preprocess_image(self, message: PhotoMessage):
return image
self.preprocess_image = MethodType(preprocess_image, self)
def _crop(self, message: PhotoMessage, image: Image.Image):
return image
def _resize(self, message: PhotoMessage, image: Image.Image):
return image.resize(self.preprocess["size"])
|
随后继承该类,定义一个IdentificationModel子类,新增一个_loadmodel功能,需要返回一个predict方法。
1
2
3
4
5
6
7
8
9
10
11
| class IdentificationModel(BaseModel):
def __init__(self, config: Dict[str, Any]):
super().__init__(config)
self.predict = self._loadmodel()
def _loadmodel(self):
predict = ModelLoader.loader(self.name, self.pipeline, self.device)
return predict
def __str__(self):
return self.name
|
由于当前模型都暂时只需要一个predict方法,因此,暂时只使用该子类。可以注意到,IdentificationModel类使用了一个ModelLoader类,该类负责每个具体的识别模型的predict逻辑,返回每个模型中我们需要的predict函数,由于过于冗长,不做展示。
基于上述类,consumer线程可以很轻松的从配置文件中加载模型:
1
2
3
| self.modellist = []
for config in config_list:
self.modellist.append(IdentificationModel(config))
|
并逐个调用模型对图片进行识别:
1
2
3
| for model in self.modellist:
photo = model.preprocess_image(message)
output = model.predict(message, photo)
|
当然,在consumer内部也采用了多线程的设计,此处不再赘述。
存储模块设计
存储模块负责将识别结果整理后存入Postgresql数据库,识别结果图片存入Minio桶容器,之间通过唯一的uuid相关联,此处不多赘述。
容器化部署
由于本项目涉及到深度学习环境以及redis、minio、psql等工具,因此,使用docker部署是最快速最安全的方式。但是这里有个大坑!我原本基于dockerfile构建了带cuda驱动、nvcc、python环境以及ffmpeg等的容器,但是发现,由于windows上的docker是机遇wsl实现的,和本机之间存在网络的隔离,在容器内运行的python程序读不到局域网下的rtsp流。本人当即表示烦。
无奈,只能暂时线把主要程序放在宿主机上执行,redis、minio、psql使用docker部署。该项目的docker-compose如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| version: '3.8'
services:
redis:
image: redis:7
container_name: labsecurity_redis
ports:
- "6379:6379"
restart: always
minio:
image: minio/minio
container_name: labsecurity_minio
ports:
- "9000:9000"
- "9001:9001"
environment:
MINIO_ROOT_USER: minioadmin
MINIO_ROOT_PASSWORD: minioadmin
command: server /data --console-address ":9001"
volumes:
- minio_data:/data
restart: always
minio-init:
image: minio/mc
depends_on:
- minio
entrypoint: >
/bin/sh -c "
sleep 5;
mc alias set local http://minio:9000 minioadmin minioadmin;
mc mb -p local/detection-results;
mc policy set public local/detection-results;
exit 0;
"
postgres:
image: postgres:17
container_name: labsecurity_postgres
environment:
POSTGRES_DB: labcamera
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
ports:
- "5434:5432"
volumes:
- ./initdb:/docker-entrypoint-initdb.d
restart: always
volumes:
pgdata:
minio_data:
|
其中,在labsecurity_postgres容器中,我指定了数据库初始化的文件位置,即/initdb,只要在该文件夹下放置.sql,容器初始化时即可根据该sql文件建立数据库,不要太方便。而容器间、宿主机和容器间也可以通过端口相互访问,例如,在其他容器内通过minio:9000,在本机中可以通过http://localhost:9001/访问。
通过 docker compose up -d 可以一键部署容器,通过 docker ps` -a 查看部署情况。此外,按照原计划,深度学习环境也会部署在容器内,这里做个记录,首先,构建 .Dockerfile:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| FROM nvidia/cuda:12.8.0-cudnn-runtime-ubuntu22.04
RUN apt-get update && apt-get install -y python3 python3-pip
WORKDIR /app
COPY requirements.txt .
RUN pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu126
RUN pip install --no-cache-dir -r requirements.txt
COPY ./app /app
CMD ["python3", "main.py"]
|
可以看到,该文件指定了安装cuda驱动和python,并根据requirements安装好需要的python包。在docker- compose中加上:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| services:
app:
build: .
runtime: nvidia
container_name: labsecurity_app
depends_on:
- redis
- postgres
- minio
volumes:
- ./app:/app
working_dir: /app
ports:
- "8888:8888"
command: ["tail", "-f", "/dev/null"]
|
容器能看到本机的 ./app 目录,点击vscode左下方的><,选择Attach to Running Container,进入python容器,就可以愉快的开发了。
总结
这算是我参与的算是比较完整的横向了,但是也没什么好总结的,懒得总结。